Program
The previous examples in the logr documentation were intentionally simplified to focus on the workings of a particular function. It is helpful, however, to also view logr functions in the context of a complete program. The following example shows a complete program. The example illustrates how logr functions work together, and interact with tidyverse and sassy functions to create a comprehensive log.
This example has been chosen because it incorporates many of the functions that will log automatically. If you want to maximize the auto-generation features of logr, take note of these functions.
The data for this example has been included in the
logr package as an external data file. It may be
accessed using the system.file() function as shown below,
or downloaded directly from the logr GitHub site here
library(tidyverse)
library(sassy)
options("logr.autolog" = TRUE)
# Get temp location for log and report output
tmp <- tempdir()
# Open the log
lf <- log_open(file.path(tmp, "example1.log"))
# Send code to the log
log_code()
sep("Load the data")
# Get path to sample data
pkg <- system.file("extdata", package = "logr")
# Define data library
libname(sdtm, pkg, "csv")
# Prepare Data -------------------------------------------------------------
sep("Prepare the data")
# Define format for age groups
ageg <- value(condition(x > 18 & x <= 29, "18 to 29"),
condition(x >= 30 & x <= 44, "30 to 44"),
condition(x >= 45 & x <= 59, "45 to 59"),
condition(TRUE, "60+"))
# Manipulate data
final <- sdtm$DM %>%
select(USUBJID, BRTHDTC, AGE) %>%
mutate(AGEG = fapply(AGE, ageg)) %>%
arrange(AGEG, AGE) %>%
group_by(AGEG) %>%
datastep(retain = list(SEQ = 0),
calculate = {AGEM <- mean(AGE)},
attrib = list(USUBJID = dsattr(label = "Universal Subject ID"),
BRTHDTC = dsattr(label = "Subject Birth Date",
format = "%m %B %Y"),
AGE = dsattr(label = "Subject Age in Years",
justify = "center"),
AGEG = dsattr(label = "Subject Age Group",
justify = "left"),
AGEB = dsattr(label = "Age Group Boundaries"),
SEQ = dsattr(label = "Subject Age Group Sequence",
justify = "center"),
AGEM = dsattr(label = "Mean Subject Age",
format = "%1.2f"),
AGEMC = dsattr(label = "Subject Age Mean Category",
format = c(B = "Below", A = "Above"),
justify = "right")),
{
# Start and end of Age Groups
if (first. & last.)
AGEB <- "Start - End"
else if (first.)
AGEB <- "Start"
else if (last.)
AGEB <- "End"
else
AGEB <- "-"
# Sequence within Age Groups
if (first.)
SEQ <- 1
else
SEQ <- SEQ + 1
# Above or Below the mean age
if (AGE > AGEM)
AGEMC <- "A"
else
AGEMC <- "B"
}) %>%
ungroup() %>%
put()
# Put dictionary to log
dictionary(final) %>% put()
# Create Report ------------------------------------------------------------
sep("Create report")
# Create table
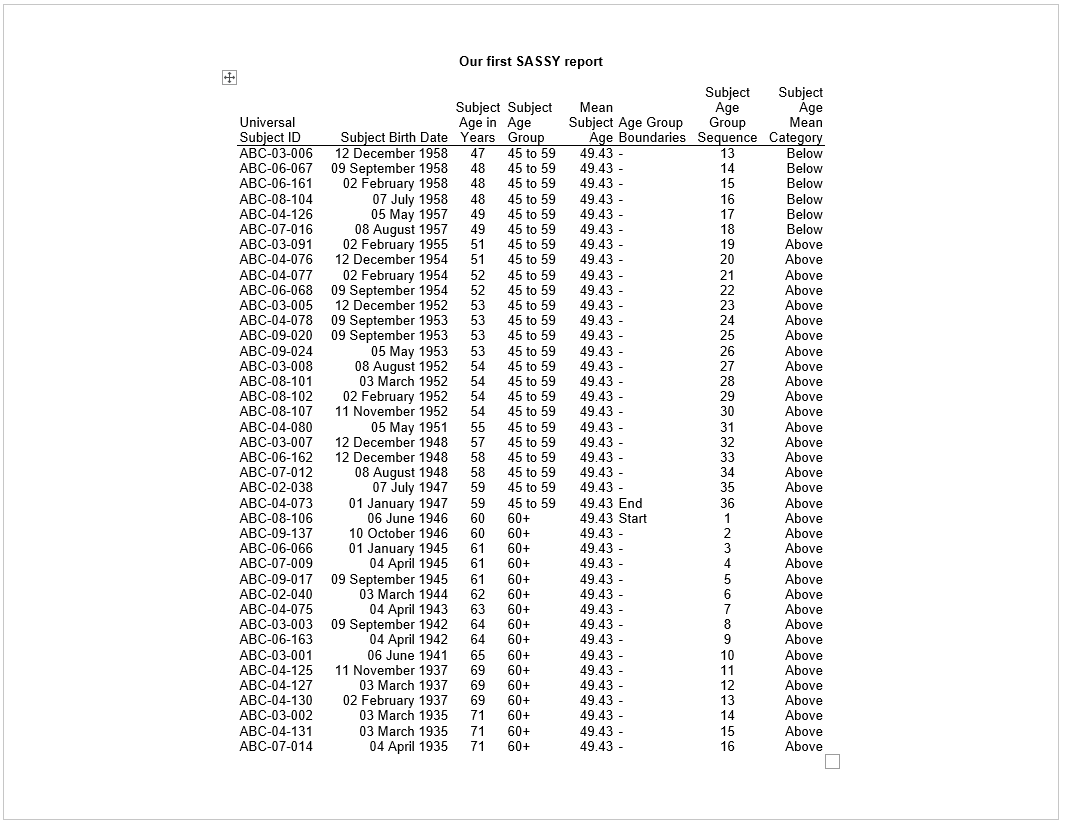
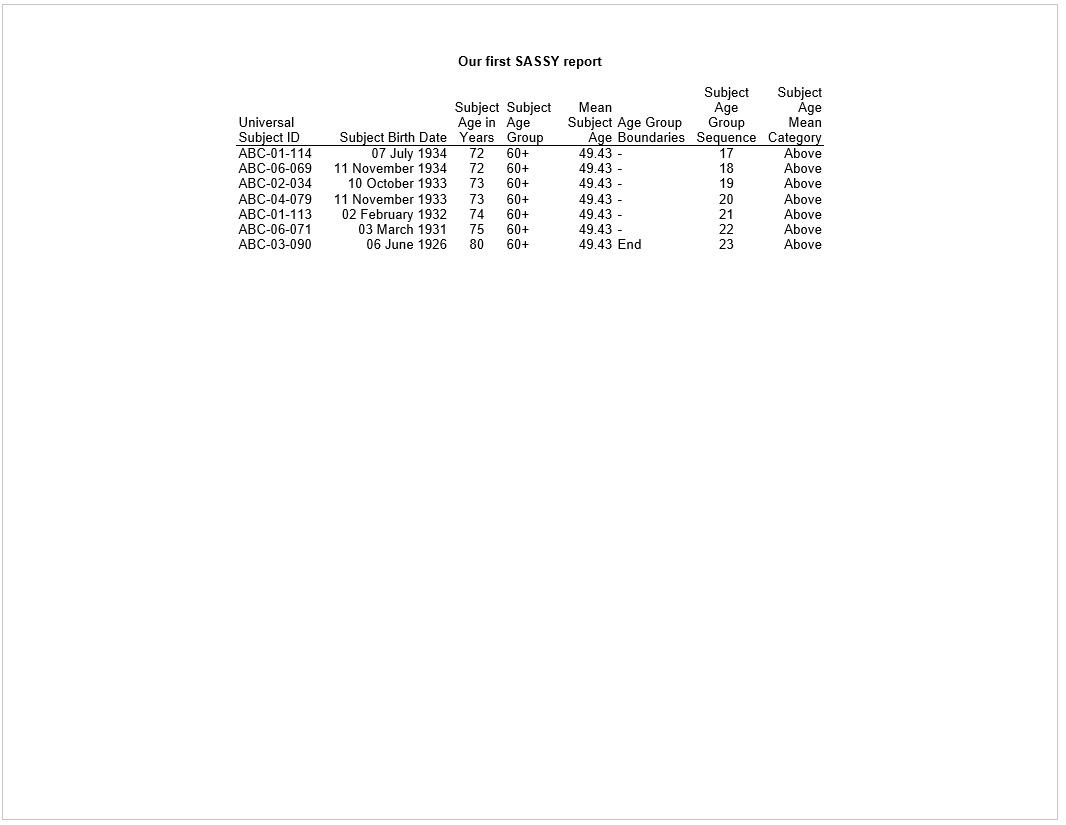
tbl <- create_table(final)
# Create report
rpt <- create_report(file.path(tmp, "./output/example1.rtf"),
output_type = "RTF", font = "Arial") %>%
titles("Our first SASSY report", bold = TRUE) %>%
add_content(tbl)
# write out the report
res <- write_report(rpt)
# Clean Up -----------------------------------------------------------------
sep("Clean Up")
# Close the log
log_close()
# View Report
# file.show(res$modified_path)
# View Log
# file.show(lf)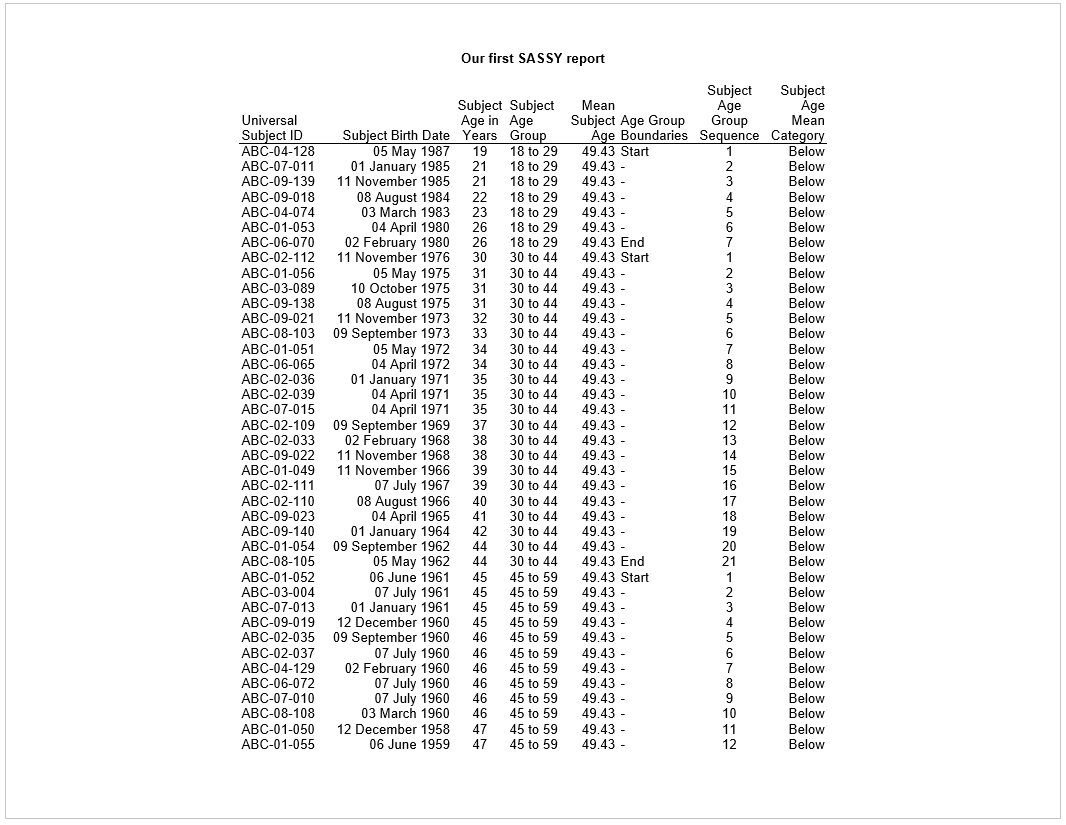
Log
The above program produces the following log:
=========================================================================
Log Path: C:/Users/dbosa/AppData/Local/Temp/Rtmpw1TuO2/log/example1.log
Program Path: C:/packages/Testing/LogTest24.R
Working Directory: C:/packages/Testing
User Name: dbosa
R Version: 4.4.2 (2024-10-31 ucrt)
Machine: SOCRATES x86-64
Operating System: Windows 10 x64 build 26100
Base Packages: stats graphics grDevices utils datasets methods base
Other Packages: tidylog_1.1.0 procs_1.0.7 reporter_1.4.4 libr_1.3.4 logr_1.3.9
fmtr_1.6.5 common_1.1.3 sassy_1.2.5 lubridate_1.9.3 forcats_1.0.0 stringr_1.5.1
dplyr_1.1.4 purrr_1.0.2 readr_2.1.5 tidyr_1.3.1 tibble_3.2.1 ggplot2_3.5.1
tidyverse_2.0.0
Log Start Time: 2025-03-26 12:50:40.218714
=========================================================================
> library(tidyverse)
> library(sassy)
>
> options("logr.autolog" = TRUE)
>
> # Get temp location for log and report output
> tmp <- tempdir()
>
> # Open the log
> lf <- log_open(file.path(tmp, "example1.log"))
>
> # Send code to the log
> log_code()
>
> sep("Load the data")
>
> # Get path to sample data
> pkg <- system.file("extdata", package = "logr")
>
> # Define data library
> libname(sdtm, pkg, "csv")
>
> # Prepare Data -------------------------------------------------------------
> sep("Prepare the data")
>
> # Define format for age groups
> ageg <- value(condition(x > 18 & x <= 29, "18 to 29"),
> condition(x >= 30 & x <= 44, "30 to 44"),
> condition(x >= 45 & x <= 59, "45 to 59"),
> condition(TRUE, "60+"))
>
>
> # Manipulate data
> final <- sdtm$DM %>%
> select(USUBJID, BRTHDTC, AGE) %>%
> mutate(AGEG = fapply(AGE, ageg)) %>%
> arrange(AGEG, AGE) %>%
> group_by(AGEG) %>%
> datastep(retain = list(SEQ = 0),
> calculate = {AGEM <- mean(AGE)},
> attrib = list(USUBJID = dsattr(label = "Universal Subject ID"),
> BRTHDTC = dsattr(label = "Subject Birth Date",
> format = "%m %B %Y"),
> AGE = dsattr(label = "Subject Age in Years",
> justify = "center"),
> AGEG = dsattr(label = "Subject Age Group",
> justify = "left"),
> AGEB = dsattr(label = "Age Group Boundaries"),
> SEQ = dsattr(label = "Subject Age Group Sequence",
> justify = "center"),
> AGEM = dsattr(label = "Mean Subject Age",
> format = "%1.2f"),
> AGEMC = dsattr(label = "Subject Age Mean Category",
> format = c(B = "Below", A = "Above"),
> justify = "right")),
> {
>
> # Start and end of Age Groups
> if (first. & last.)
> AGEB <- "Start - End"
> else if (first.)
> AGEB <- "Start"
> else if (last.)
> AGEB <- "End"
> else
> AGEB <- "-"
>
> # Sequence within Age Groups
> if (first.)
> SEQ <- 1
> else
> SEQ <- SEQ + 1
>
> # Above or Below the mean age
> if (AGE > AGEM)
> AGEMC <- "A"
> else
> AGEMC <- "B"
>
> }) %>%
> ungroup() %>%
> put()
>
> # Put dictionary to log
> dictionary(final) %>% put()
>
> # Create Report ------------------------------------------------------------
> sep("Create report")
>
>
> # Create table
> tbl <- create_table(final)
>
> # Create report
> rpt <- create_report(file.path(tmp, "./output/example1.rtf"),
> output_type = "RTF", font = "Arial") %>%
> titles("Our first SASSY report", bold = TRUE) %>%
> add_content(tbl)
>
> # write out the report
> res <- write_report(rpt)
>
>
> # Clean Up -----------------------------------------------------------------
> sep("Clean Up")
>
> # Close the log
> log_close()
>
> # View Report
> # file.show(res$modified_path)
>
> # View Log
> # file.show(lf)
>
>
>
=========================================================================
Load the data
=========================================================================
# library 'sdtm': 1 items
- attributes: csv not loaded
- path: C:/Users/dbosa/AppData/Local/R/win-library/4.4/logr/extdata
- items:
Name Extension Rows Cols Size LastModified
1 DM csv 87 24 45.8 Kb 2025-03-26 11:02:29
NOTE: Log Print Time: 2025-03-26 12:50:40.733955
NOTE: Elapsed Time: 0.511612892150879 secs
=========================================================================
Prepare the data
=========================================================================
# A user-defined format: 4 conditions
Name Type Expression Label Order
1 obj U x > 18 & x <= 29 18 to 29 NA
2 obj U x >= 30 & x <= 44 30 to 44 NA
3 obj U x >= 45 & x <= 59 45 to 59 NA
4 obj U TRUE 60+ NA
NOTE: Log Print Time: 2025-03-26 12:50:40.74675
NOTE: Elapsed Time: 0.0127952098846436 secs
select: dropped 21 variables (STUDYID, DOMAIN, SUBJID, RFSTDTC, RFENDTC, …)
NOTE: Log Print Time: 2025-03-26 12:50:40.759215
NOTE: Elapsed Time: 0.0124650001525879 secs
mutate: new variable 'AGEG' (character) with 4 unique values and 0% NA
NOTE: Log Print Time: 2025-03-26 12:50:40.779213
NOTE: Elapsed Time: 0.0199978351593018 secs
group_by: one grouping variable (AGEG)
NOTE: Log Print Time: 2025-03-26 12:50:40.79064
NOTE: Elapsed Time: 0.0114271640777588 secs
datastep: columns increased from 4 to 8
NOTE: Log Print Time: 2025-03-26 12:50:40.911893
NOTE: Elapsed Time: 0.121252775192261 secs
# A tibble: 87 × 8
# Groups: AGEG [4]
USUBJID BRTHDTC AGE AGEG AGEM AGEB SEQ AGEMC
<chr> <date> <dbl> <chr> <dbl> <chr> <dbl> <chr>
1 ABC-04-128 1987-05-24 19 18 to 29 49.4 Start 1 B
2 ABC-07-011 1985-01-18 21 18 to 29 49.4 - 2 B
3 ABC-09-139 1985-11-13 21 18 to 29 49.4 - 3 B
4 ABC-09-018 1984-08-29 22 18 to 29 49.4 - 4 B
5 ABC-04-074 1983-03-28 23 18 to 29 49.4 - 5 B
6 ABC-01-053 1980-04-07 26 18 to 29 49.4 - 6 B
7 ABC-06-070 1980-02-01 26 18 to 29 49.4 End 7 B
8 ABC-02-112 1976-11-01 30 30 to 44 49.4 Start 1 B
9 ABC-01-056 1975-05-02 31 30 to 44 49.4 - 2 B
10 ABC-03-089 1975-10-02 31 30 to 44 49.4 - 3 B
# ℹ 77 more rows
# ℹ Use `print(n = ...)` to see more rows
NOTE: Data frame has 87 rows and 8 columns.
NOTE: Log Print Time: 2025-03-26 12:50:40.993307
NOTE: Elapsed Time: 0.0814142227172852 secs
ungroup: no grouping variables remain
NOTE: Log Print Time: 2025-03-26 12:50:41.067702
NOTE: Elapsed Time: 0.0743949413299561 secs
# A tibble: 87 × 8
USUBJID BRTHDTC AGE AGEG AGEM AGEB SEQ AGEMC
<chr> <date> <dbl> <chr> <dbl> <chr> <dbl> <chr>
1 ABC-04-128 1987-05-24 19 18 to 29 49.4 Start 1 B
2 ABC-07-011 1985-01-18 21 18 to 29 49.4 - 2 B
3 ABC-09-139 1985-11-13 21 18 to 29 49.4 - 3 B
4 ABC-09-018 1984-08-29 22 18 to 29 49.4 - 4 B
5 ABC-04-074 1983-03-28 23 18 to 29 49.4 - 5 B
6 ABC-01-053 1980-04-07 26 18 to 29 49.4 - 6 B
7 ABC-06-070 1980-02-01 26 18 to 29 49.4 End 7 B
8 ABC-02-112 1976-11-01 30 30 to 44 49.4 Start 1 B
9 ABC-01-056 1975-05-02 31 30 to 44 49.4 - 2 B
10 ABC-03-089 1975-10-02 31 30 to 44 49.4 - 3 B
# ℹ 77 more rows
# ℹ Use `print(n = ...)` to see more rows
NOTE: Data frame has 87 rows and 8 columns.
NOTE: Log Print Time: 2025-03-26 12:50:41.219635
NOTE: Elapsed Time: 0.151932954788208 secs
# A tibble: 8 × 11
Name Column Class Label Description Format Width Justify Rows NAs MaxChar
<chr> <chr> <chr> <chr> <chr> <chr> <lgl> <chr> <int> <int> <int>
1 final USUBJID charact… Univ… <NA> <NA> NA <NA> 87 0 10
2 final BRTHDTC Date Subj… <NA> "%m %… NA <NA> 87 0 10
3 final AGE numeric Subj… <NA> <NA> NA center 87 0 2
4 final AGEG charact… Subj… <NA> <NA> NA left 87 0 8
5 final AGEM numeric Mean… <NA> "%1.2… NA <NA> 87 0 16
6 final AGEB charact… Age … <NA> <NA> NA <NA> 87 0 5
7 final SEQ numeric Subj… <NA> <NA> NA center 87 0 2
8 final AGEMC charact… Subj… <NA> "Belo… NA right 87 0 1
NOTE: Data frame has 8 rows and 11 columns.
NOTE: Log Print Time: 2025-03-26 12:50:41.40138
NOTE: Elapsed Time: 0.181745052337646 secs
=========================================================================
Create report
=========================================================================
# A report specification: 3 pages
- file_path: 'C:\Users\dbosa\AppData\Local\Temp\Rtmpw1TuO2/./output/example1.rtf'
- output_type: RTF
- units: inches
- orientation: landscape
- margins: top 0.5 bottom 0.5 left 1 right 1
- line size/count: 9/42
- title 1: 'Our first SASSY report'
- content:
# A table specification:
- data: tibble 'final' 87 rows 8 cols
- show_cols: all
- use_attributes: all
NOTE: Log Print Time: 2025-03-26 12:50:41.999186
NOTE: Elapsed Time: 0.597805976867676 secs
=========================================================================
Clean Up
=========================================================================
=========================================================================
Log End Time: 2025-03-26 12:50:42.151877
Log Elapsed Time: 0 00:00:01
=========================================================================